
IT Maker: Big & Wide Data
Con un almacenamiento en la nube infinitamente escalable, la restricción de almacenamientos masivos de datos ha desaparecido. Ahora es más sencillo mover las bases de datos desde las infraestructuras on-premise hacia la nube. Con determinados criterios y procedimientos se definen qué datos estarán en alguna (o varias) de las nubes como así también cuáles datos quedarán on-premise. Y ahora nos preguntamos, ¿qué sigue? Y la respuesta es, Wide Data altamente distribuidos.
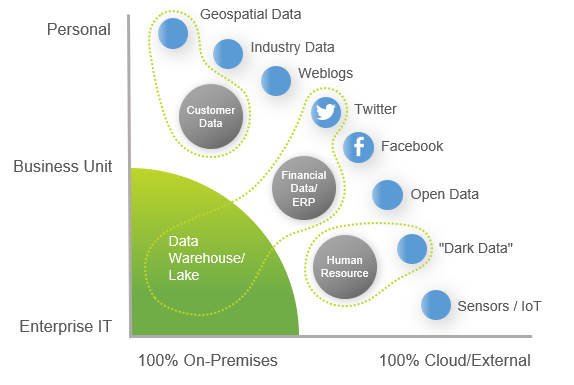
Para obtener el mayor valor posible de su Big & Wide Data, se debe brindar a toda la organización, no sólo a los científicos de datos, el poder de explorar, comprender y hacer descubrimientos dentro de ella.
La apertura de su Big & Wide Data dentro de una organización permitirá obtener información sobre nuevas áreas dónde operar; crear una cultura de curiosidad, donde la experiencia y la “intuición” se complementan con evidencia; y por último, al disponer de todos los datos, se lograrán más y mejores descubrimientos.
Para ello, Qlik Associative Big Data Index ™ acelera el descubrimiento de datos en volúmenes de datos masivos. Para maximizar el rendimiento utiliza Qlik Selection Language (QSL), que precisamente no es SQL.
QSL es un lenguaje de estado de selección de alta velocidad para que las organizaciones realicen la extracción de datos a través del índice, en lugar de editar y ejecutar grandes SQL’s directamente contra el repositorio de datos. El resultado es un rendimiento y una agilidad incomparables.
Por su parte, con Qlik Associative Big Data (QABD) las personas pueden explorar información actualizada porque el índice de QABD se actualiza de inmediato cuando cambia cualquier dato en la fuente.
Asimismo, las organizaciones pueden usar Qlik Associative Big Data para resolver múltiples escenarios:
| Modo de secuencia de comandos | Modo On-Demand App Generation (ODAG) | Modo en vivo |
| Un nuevo conector Qlik Associative Big Data Index está disponible a través del editor de carga de datos que permite a los usuarios generar automáticamente una secuencia de comandos que contiene filtros de datos definidos por el usuario. | Mejora las implementaciones ODAG existentes al acelerar la solicitud y entrega de datos seleccionados para la aplicación detallada. | Se puede consultar directamente el Data Lake usando este modo evitando el motor asociativo en memoria, todo sin necesidad de mover datos a la memoria. |
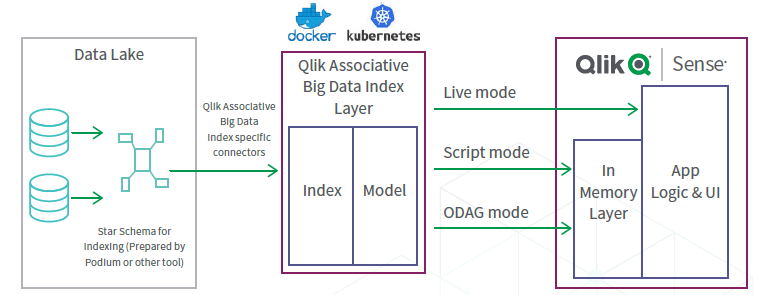
Qlik Associative Big Data mueve el poder de asociación de la interfaz de usuario al ecosistema
de productos Qlik, indexando y almacenando información dentro de la fuente de datos, todo
sin tener que cargar datos en la memoria.
En IT Maker creemos que cuando empoderás a tu gente, para que tomen acciones sobre ideas y descubrimientos, es cuando realmente se crea valor, por eso ayudamos a las personas a mejorar la forma en que sintetizan y analizan Big and Wide Data.
Por Flavio Fazzano
Director de IT Maker.


