Cómo aplicar la tecnología para el análisis de imágenes y de texto
Continuamos con la presentación de la selección de artículos exhibidos en la Conferencia Internacional de Transformación Digital e Innovación Tecnológica (INCODTRIN), organizada en octubre del 2020, por IOT & Big Data Services y BigDaSS. Esta vez, se trata de investigaciones que hacen hincapié en el uso de la tecnología para la detección de objetos, y para el análisis de textos, con información extraída de las redes sociales.
Detección de objetos en caminos rurales utilizando Tensorflow
Los sistemas de visión por computadora (CV) o visión artificial han experimentado un gran desarrollo en el campo de la inteligencia artificial en los últimos años. Uno de los aspectos a considerar para este crecimiento ha sido no limitarse solo a nichos como la robótica y la fabricación, sino también implementarse en otras áreas como la domótica, la detección inteligente, el análisis de imágenes médicas, y la industria alimentaria, entre otras.
Hay muchas actividades de investigación que se llevan a cabo en el área de CV, una de las principales es la detección de objetos.
El objetivo principal de esta investigación fue localizar la existencia de algún objeto, como un vehículo, una persona, una moto o bicicleta, en una imagen, de tal manera que si se encontrase uno, el objeto se visualice a través de cuadros delimitadores. Es decir, la pregunta de investigación fue: ¿Cuál de los modelos existentes en el campo de objeto de detección y clasificación resulta ser el mejor?.
En este contexto se propuso utilizar la API de detección de objetos de TensorFlow, basada en la combinación de redes neuronales convolucionales profundas (CNN). Se analizó el rendimiento de los marcos más rápidos de R-CCN, R-FCN y SDD. También se probaron estos modelos en un conjunto de datos elaborado por el equipo de investigación.
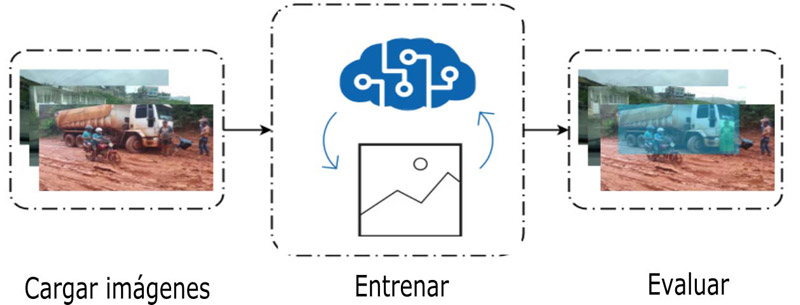
Del estudio se desprendió que el modelo Faster R-CNN ResNet 50 proporcionó un alto rendimiento en el reconocimiento de bicicletas, motos y automóviles; sin embargo, los modelos Faster R-CNN Inception V2 resultaron mejores en la detección de bicicletas y motos en escenarios complejos.
La mayoría de los estudios hicieron hincapié en la resolución de problemas en vías urbanas donde las vías están bien mantenidas y claramente delimitadas. Por el contrario, estas técnicas no funcionan en aquellas ámbitos no desarrollados, como las áreas rurales.

Luis Barba-Guaman y Anthony Ortiz
Laboratorio de Inteligencia Artificial
Universidad Técnica Particular de Loja, Ecuador.
lrbarba@utpl.edu.ec
ajortiz4@utpl.edu.ec
José Eugenio Naranjo
INSIA- Universidad Politécnica de Madrid, España.
joseeugenio.naranjo@upm.es
Evaluación de las herramientas de reconocimiento de entidades nombradas (NER) vs. algoritmos adaptados a la extracción de localizaciones
Actualmente, hay mucha información escrita en lenguaje coloquial proveniente de sitios web y redes sociales, de donde se extrae información valiosa. Sin embargo, la información se transmite en textos no estructurados, y no es fácil analizarlo, por lo que se utilizan técnicas de extracción de información (IE).
El proceso de IE tiene como finalidad analizar textos y extraer información de interés para el usuario, de manera eficiente e incluso permite almacenarse en bases de datos.
El IE consta de varias tareas, una de ellas es el sistema de reconocimiento (NER). NER tiene un papel importante por ejemplo para la búsqueda automática de respuestas y categorización de textos. Los sistemas NER tienen herramientas para clasificar cada tipo de entidades (una persona, una ubicación, o una organización) a través de la aplicación de diferentes metodologías en varios dominios e idiomas.
Otra técnica utilizada para IE son los algoritmos adaptados, como los de similitud y distancia. En la ciencia informática, uno de los principales es el algoritmo de distancia de Levenshtein.
La aplicación de estos métodos permite extraer información útil de un dominio de interés para estructurarla y analizarla. Sin embargo, dado que existen varios de éstos con el mismo propósito, es difícil determinar la técnica adecuada, y que se adapte a necesidades particulares, como la extracción de etiquetas de localización en español.
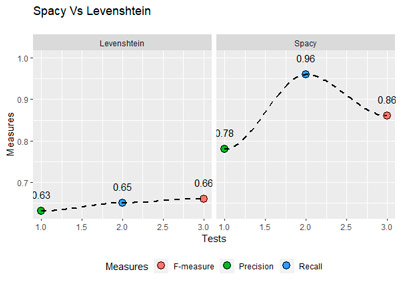
En esta investigación, se propuso evaluar la técnica NER a través de la biblioteca SpaCy, y el algoritmo de Levenshtein con la finalidad de determinar cuál es la más adecuada para identificar la ubicación de calles o lugares en la ciudad de Cuenca, Ecuador. Para la evaluación, se obtuvieron datos de la red social Twitter, a partir de tweets cuyo contenido hacía referencia a accidentes de tránsito durante el periodo de enero y diciembre de 2017. Asimismo se utilizaron etiquetas de localización, es decir, textos basados en parámetros de precisión, recuperación y “Valor-F”. Los resultados revelaron que la biblioteca Spacy resultó superadora en todas las métricas.
Marcos Orellana y Catalina Fárez
Universidad del Azuay, Cuenca-Ecuador.
marore@uazuay.edu.ec
cfarez19@es.uazuay.edu.ec
Paúl Cárdenas
Universidad de Cuenca, Ecuador.
paul.cardenas@ucuenca.edu.ec